BeautifulSoup是Python的一个库, 最主要的功能是从网页抓取数据 。
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
官方文档 >> BeautifulSoup中文文档
1、BeautifulSoup的安装
1 | pip install BeautifulSoup4 |
2、BeautifulSoup的使用
1 | html_doc = "<html><head><title>The Dormouse's story</title></head><body><p class='title'><b>The Dormouse's story</b></p><p class='story'>Once upon a time there were three little sisters; and their names were<a href='http://example.com/elsie' class='sister' id='link1'>Elsie</a>,<a href='http://example.com/lacie' class='sister' id='link2'>Lacie</a> and<a href='http://example.com/tillie' class='sister' id='link3'>Tillie</a>;and they lived at the bottom of a well.</p><p class='story'>...</p>" |
3、BeautifulSoup 类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标注开头和结尾,如上面的soup.a |
| Name | 标签的名字, … 的名字是’p’,如上面的soup.a.name |
| Attributes | 标签的属性,字典形式组织,如上面的 soup.a.attrs['id'] |
| NavigableString | 标签内非属性字符串,<>…</>中的字符串,如上面的 soup.a.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
4、基于bs4的HTML内容遍历方法
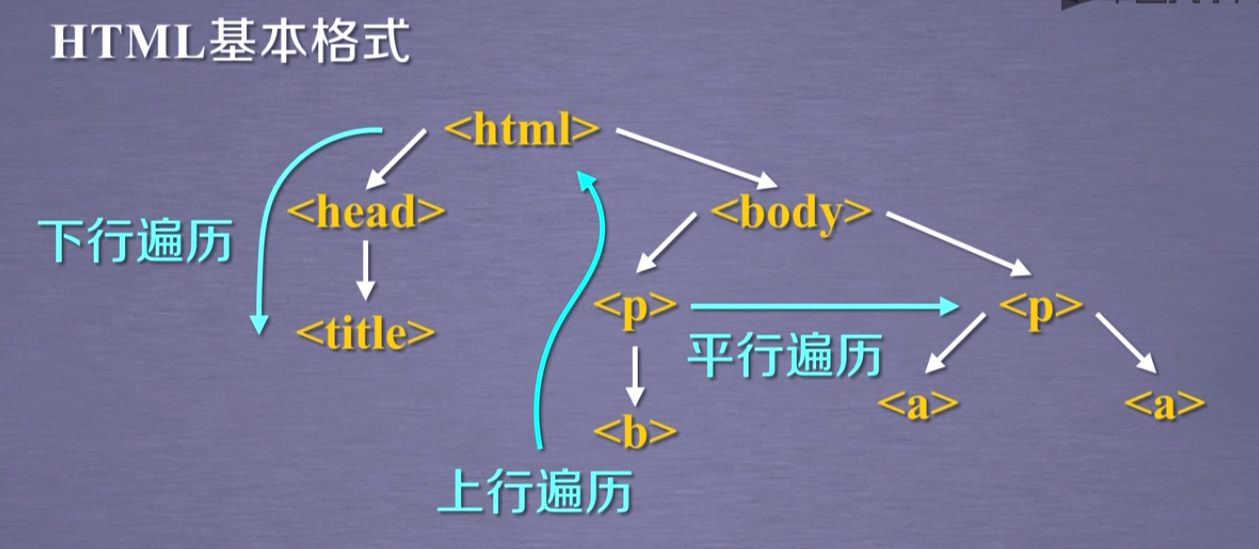
上行遍历
属性 说明 .parent 节点的父亲标签 .parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
下行遍历
属性 说明 .contents 子节点的列表,将 所有儿子节点存入列表 .children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 .descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
平行遍历
属性 说明 .next_sibling 返回按照HTML文本顺序的下一个平行节点的标签 .previous_sibling 返回按照HTML文本顺序的上一个平行节点标签 .next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 .previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点的标签
5、HTML内容格式化
prettify()方法
1 | print(soup.pettify()) |
6、内容提取
.find_all(name, attrs, recursive, string, **kwargs)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
attrs:对标签属性值得检索字符串,可标注属性检索
recursive:是否对子孙全部检索,默认为True
string:<>…</>中字符串区域的检索字符串
